Basics of dimesional modeling
Dimensional Modeling
Introduction
In the last article, I covered the data warehouse architecture. In order to leverage data warehouse to its full potential and get most out of the data, data modeling becomes a crucial part. Dimensional modeling is a very popular choice for analytical data loads. It is widely popular due to performance improvements over transactional/normalized data and also it makes it very easy to understand the data. Due to the simplicity, it also helps to deliver business value quickly. Essentially dimensional data is contains the same information as a normalized data model but organized differently in order to achieve better query performance and ease of use.
TL;DR
- Facts: Something which can be measured or aggregated. Example: Sales
- Dimension: Give context to the facts. Example: Month, Period, Product etc.
- Sales By Month
- Sales By Period
- Sales By Prodict
Here By indicates dimension.
- Star schema: Primarily used in data warehouse (dwh). Optimized for faster retrieval of data for better performance and usability.
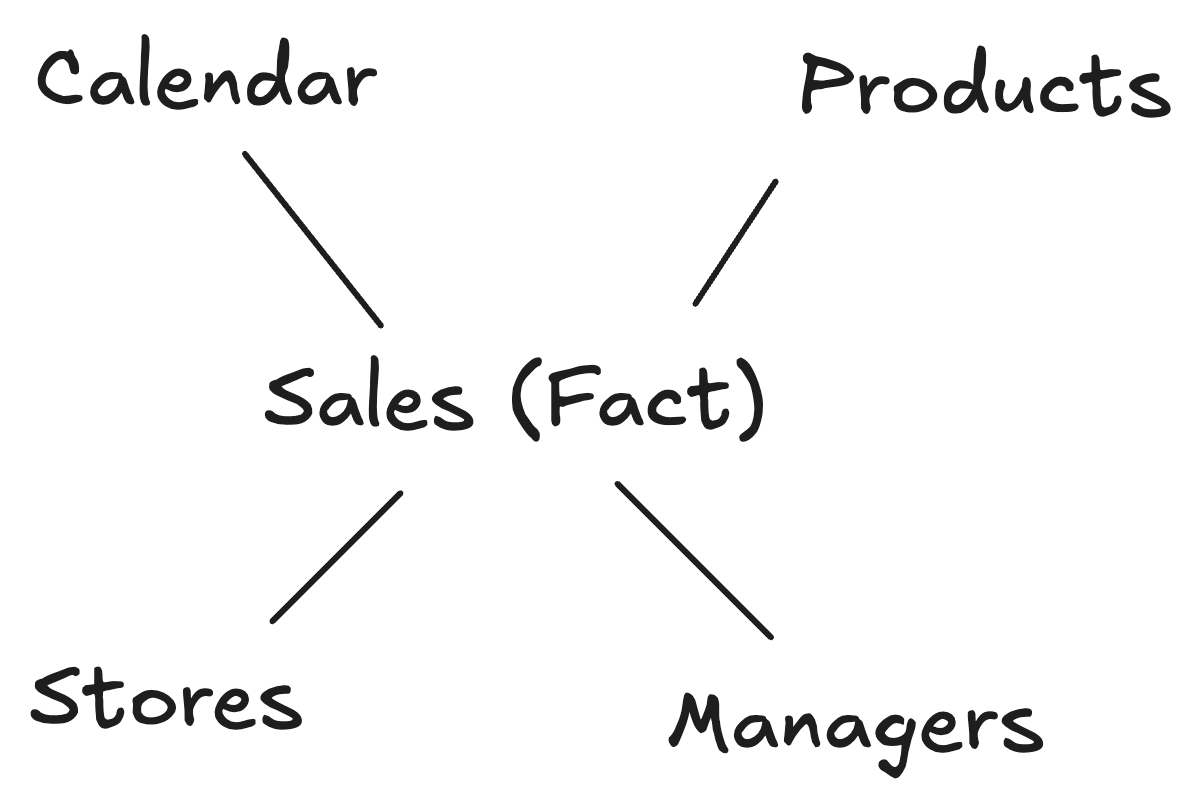
Star Schema
Dimensional model which we will see in more detail very soon can be implmented in RDBMS which is called as “star schema”. In the star schema, a fact will take the center stage and all the dimensions associated with that fact are going to form a star like structure. Due to that it is called star schema.
OLAP Cubes
When dimensional model is applied on multi dimensional database environment then it is referred to as OLAP cubes. Logically OLAP cubes and star schemas are the same but they bith are different in terms of physical implementation. Typical OLAP system contains data to improve query performance over a large dataset. Due to the implementation, indexing and optimization, OLAP works significantly well on analytical work load.
Business Process Example TO Understand Facts And Dimensions
Let us take the sales business process which can be performed through the following steps:
- Consider yourself running a small t-shirt store
- A custom collects the items to purchase in a cart
- Custmer goes to the cash counter where the cashier scans all the items one after the another
- Once all items are scanned then the customer makes the payment
- After receiving the payment, customer either gets the remaining amount back and the receipt of the purchase.
In the above case, we are collecting information for every sale that has happened in the store. Every scan on the counter represents a transaction. This also includes cancelled transaction, refund transaction etc. As a business we collect the following important entities in a transaction
- product
- qty
- unit price
- discount
- type of transaction (sale, refund, cancel etc.)
- payment type (cash, credit card, UPI etc.)
- cashier name
Facts
Facts are the entities which are used to measure the performance of various business process of an organization.
For a business, important aspect to capture is the sales that happens over the period of time is a key performance indicator. This indicator will tell the owner that how the store is performing. So in our case, qty and sales amount (qty * unit price) are going to be the fact columns.
In the above example, we are capturing every transaction that is happening at the counter, so granularity is at the transaction level. Granularity is also referred to as grain.
All the records in the fact table must have the same granularity. Most important facts are numeric and additive. In our case sales amount is the fact which can be easily added.
Adding unit price will not provide any value to the business so it can not be considered as a fact. Typically facts are something which are continuously valued.
Every fact table consists of a composit key which is a derived key created for the table. It is generally a good practive to maintain a composite key in contrast to using the existing transactional system primary key.
Dimensions
Dimensions complement the fact table. Dimension table contains all the relevant information against which the fact needs to be meansured. Dimenisions are perticularly important to slice and dice the data.
Typical dimension tables are denomalized with handful of columns which can be used to perform group by and filters on the fact tables.
So in the fact section we saw that we have sales amount as a measure. Now let us see how dimensions can give us various data points to evaluate the fact in hand.
We have 3 primary dimensions in our case:
- cashier name
- product
- date
- Cashier name dimension can answer us that which cashier is selling the most.
Sample query:
SELECT cashier, SUM(sales amount)
FROM sales_fact s
JOIN cashier_dim d ON s.cashier_id = d.cashier_id;
-
Product can give us the top selling, worst selling products etc. Here if we have additional supporting information like manufacturer, brand then it can allow business user to firther slice and dice to monitor the impact of sales by brand or manufacturer.
-
date This is one of the most common dimension and this requires a dedicated post on this. But this dimension table can answer important comparison points like sales happend this month, year, week vs last month, year, week. YTD sales, MTD sales etc which are some common use case. Depending on the sector, things may change a little but time is an essential dimention in most of the business.
Next steps
We are just scratching the surface around dimensional modeling. I will give one in depth walk thorugh a dimensional process and a quick proto type will for sure give a clear picture in your head.
Next post, i am planning to dedicate on the facts where i will describe various type of facts and most of the examples are going to be around retail domain as I have experinece working in that domain and it is a little easier for someone to understand the business processes and directly or indirectly we have been part of the retail. So for ease, we will stick to that domain and when applicable i will give other appropriate examples.
Share this post
Twitter
Reddit
LinkedIn
Pinterest
Email