
Introdunction
So far, we have explored the architecture of Databricks, Apache Spark, and the operations associated with a Spark DataFrame. There are two common approaches to data processing—batch processing and streaming. Spark provides support for both types of workloads.
In real-world scenarios, data is growing at a rapid pace, especially when considering fact tables that store transactions, logs, social media posts, etc. As these data sources grow, organizations need to apply real-time data analytics to extract insights. Data sources like logs, social media posts, and sensor data are unbounded in nature, and such continuous data flow is referred to as “data streams.” The data generated through data streams is appended to the stream over time.
In this article, we will cover incremental data processing, including Spark Structured Streaming and Auto Loader capabilities.
Streaming Data Processing Approach
There are 2 ways the streaming data source can be handled:
- Recomputation
- Incremental Processing
Here is the comparison of both the approach:
| Recompute | Incremental |
|---|---|
| Entire Dataset Processed on new data arrival | Only new data is processed |
| Accurate | Can have duplicates or data issues |
| Compute intesive | Not so compute intensive |
| Expensive to process all data everytime | Not so expensive as only new data is getting processed |
| Time consuming | Time efficient as subset of data is getting processsed |
Spark Structured Streaming
- Enables near real-time data processing.
- Provides an end-to-end fault-tolerant mechanism for streaming workloads.
- Supports Spark APIs on streaming DataFrames, making it easier to work with real-time data.
- Simplifies the transition from batch processing to streaming with minimal code changes.
- The Spark engine performs incremental and continuous updates, automatically detecting new files at the source. As new files arrive, they are processed and written to the data sink (the target write location).
Refer to the diagram below to understand the flow of a streaming workload:
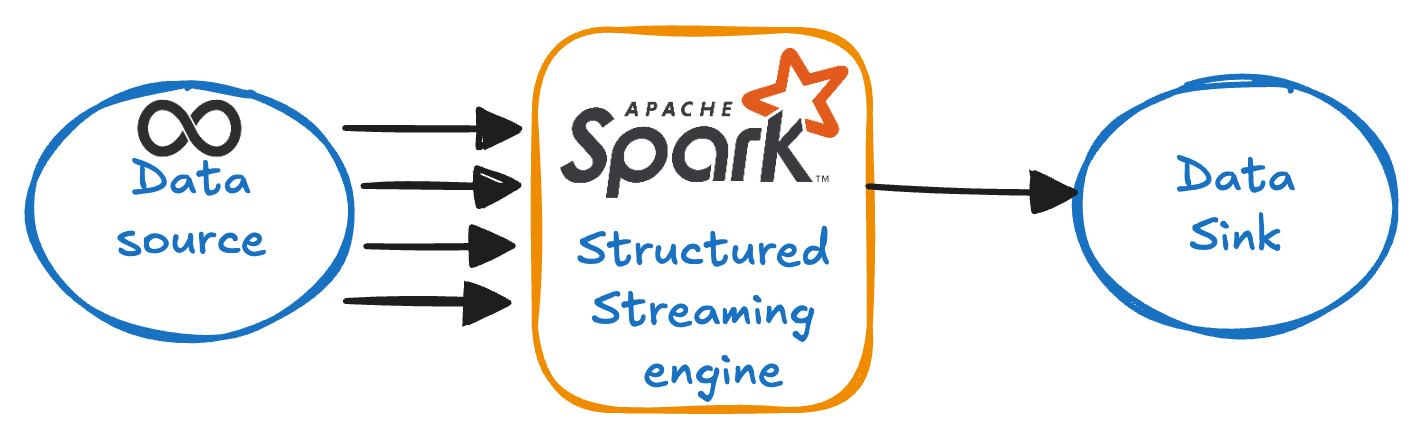
Data sink can either be files or a table. In structured streaming, data stream is handled like an unbounded, ever growing data source. Each new item is considered as a new row in the data source.
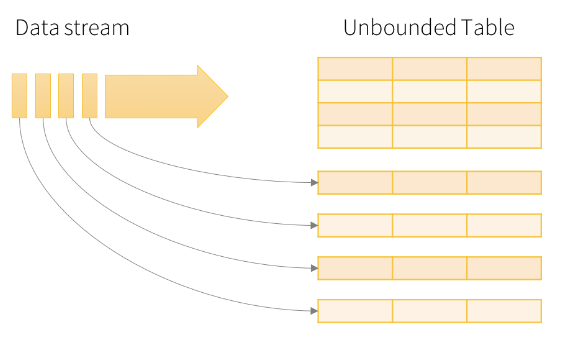
One important thing about the streaming resources is that - the data must be “append” only. This means that existing data can not be modified. If a data source is updated, deleted or overwritten then it is not considered a streaming source.
Tutorial
Environment Setup
We are going to use databricks community edition to learn these concepts. All you have to do is to sign up for the databricks community edition here. Once that is done, you are all set to follow along in this tutorial.
Once you sign in, create a cluster (In community edition you have to create a new cluster everytime and the cluster will terminate after 120 mins of inactivity)
Then create a notebook where we are going to write our code.
Setting up data for streaming workload
We are going to use cricket dataset which is available on kaggle. In order to simulate the streaming workload, I have chunked the data into multiple csv files to we can see exactly how streaming works. Chunked files which i am going to use can be downloaded from this link.
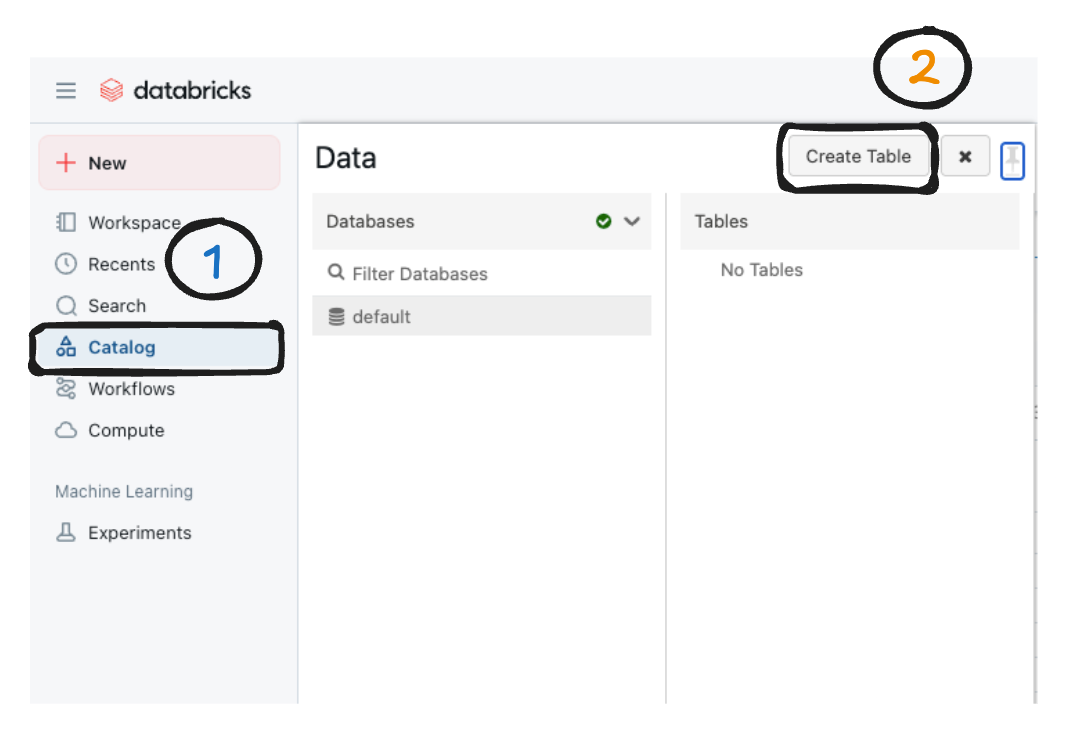
Once data is downloaded, then inside your databricks account upload the documents as shown in the below screenshot.
- Click on catalog, which will open another side menu titled data
- Click on Create Table button which will redirect you to create table page
- Under the Create New Table, specify the target directory as show in the below screenshot and upload just 1 file for now
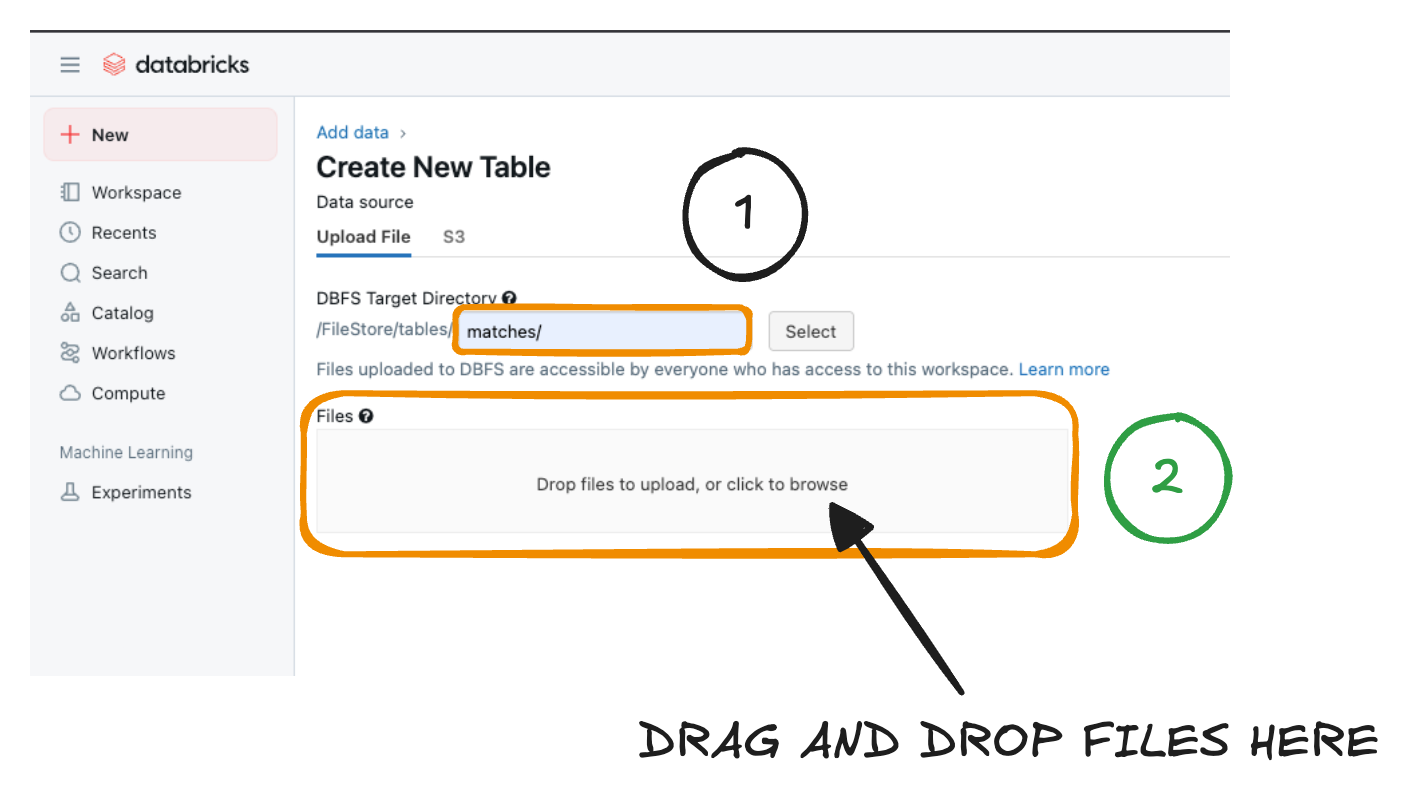
Once 1 file is uploaded, we are all set to start processing our streaming workload.
Using DataStreamReader
Now we are going to read the simulated streaming workload which is available under /FileStore/tables/matches/ location on local. In production or real-world scenario, we are going to have S3 or equvalent object storage on cloud. Let us fist confirm that, our uploaded file is present in the directory using the following command.
dbutils.fs.ls("/FileStore/tables/matches/")
Once you have file in the directory, we can start processing the data.
Let us first define the schema of the source csv files using the following code
from pyspark.sql.types import StructType, StructField, StringType, IntegerType, DateType
match_schema = StructType([
StructField("id", IntegerType(), True),
StructField("season", DateType(), True),
StructField("city", StringType(), True),
StructField("date", DateType(), True),
StructField("match_type", StringType(), True),
StructField("player_of_match", StringType(), True),
StructField("venue", StringType(), True),
StructField("team1", StringType(), True),
StructField("team2", StringType(), True),
StructField("toss_winner", StringType(), True),
StructField("toss_decision", StringType(), True),
StructField("winner", StringType(), True),
StructField("result", StringType(), True),
StructField("result_margin", IntegerType(), True),
StructField("target_runs", IntegerType(), True),
StructField("target_overs", IntegerType(), True),
StructField("super_over", StringType(), True),
StructField("method", StringType(), True),
StructField("umpire1", StringType(), True),
StructField("umpire2", StringType(), True)
])
Now we can start processing the stream data source using the following command
streaming_df = spark.readStream.option("sep", ",").schema(match_schema).csv("/FileStore/tables/matches/")
display(streaming_df)
spark.readStreamwill take/FileStore/tables/matches/as a streaming resource. This will process the existing data as well as new data arriving at the location.option("sep", ",")specifies the separator..csv("/FileStore/tables/matches/")specifies the path from which the data needs to be processed.
display(streaming_df) will trigger the streaming dataframe. As you run this command, you can see the streaming indicator and also on expansion you can monitor the streaming process as indicated in the below screenshot.
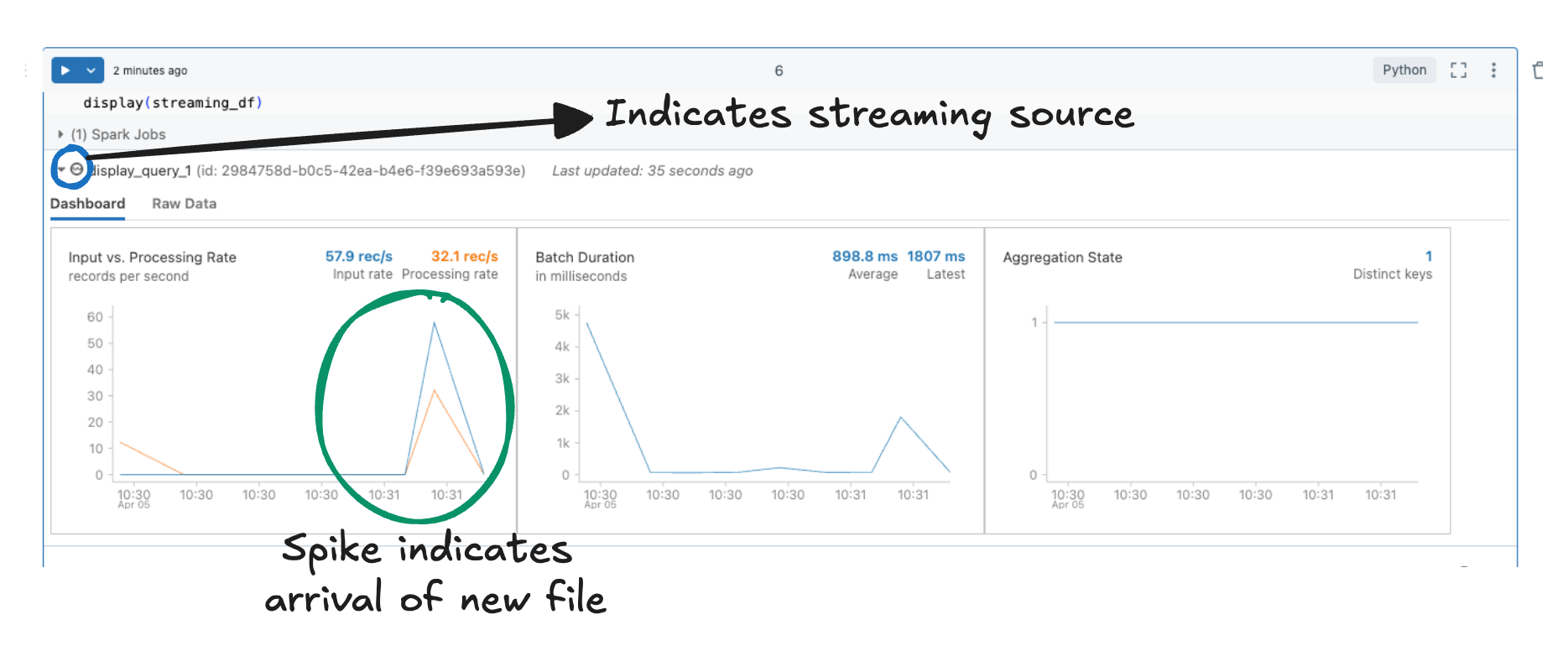
Now you can upload another file as shown in the Setting up data for streaming workload section. Once another file is uploaded, monitor the chart associated with streaming workload.
Using DataStreamWriter
Now we have to write this streaming data to a delta table so it can be consumed downstream by ETL or other jobs. Let us write this data to a delta table. Let us use the following command to write data to a delta table
streaming_df.filter(col("id").isNotNull()).writeStream \
.outputMode("append") \
.format("delta") \
.option("checkpointLocation", "/FileStore/tables/checkpoints") \
.start("/FileStore/tables/bronze/matches")
- We are writting the streaming data to
/FileStore/tables/bronze/matchesdirectory which is a delta table. checkpointLocationis an important location which helps spark keep track of the files which are processed and which files that needs to be processed.- outputMode is set to
appendwhich makes sure that all new records are appended in the data sink. filter(col("id").isNotNull())is done to elimiate the header rows from csv files. Due to schema mismatch for header rows, id will benullso as new files arrive we filter that row out to make sure we do not have headers as part of our dataset.
Now let us register this table in hive metastore. I think unity catalog is not available under community edition so i will cover it on the enterprise edition of databricks.
%sql
CREATE TABLE bronze_matches USING delta location '/FileStore/tables/bronze/matches';
The above command registers a delta table in hive metastore which can be queried directory using the following command
%sql
SELECT * FROM default.bronze_matches;
Another way to query this table is using the path directly
%sql
SELECT * FROM DELTA.`/FileStore/tables/bronze/matches`
Upon querying the delta table, you should be able to see the data. Data from csv is now available as a delta table.
Conclusion
In this article, i tried to cover basics about streaming workloads and a simple tutotial to demonstrate how streaming works. The tutorial will give you a decent idea and simulating the behavior of streaming workloads. Important thing to notice is that, in real world scenario the files are delivered in a structured and automated manner in most of the cases. Here we are uploading it manually as a workaround as databricks community edition does not allow automated document upload functionality (At least I am not aware of it at this time). I am sticking to databricks community edition so everyone who does not have access to enterprise can also follow the tutorial and understand the concepts.
Next steps
In the next article i am going to cover autoloader and some theory around COPY INTO which are also an essensial topics for incremental data processing. I will try to cover it the same way with some theory, followed by tutorial.