
TL;DR
This post introduces Databricks, a data intelligence platform that combines the best features of data warehouses and data lakes in a lakehouse architecture. It covers Databricks’ key components, underlying architecture, Apache Spark integration, and provides guidance on how to get started using the Databricks Community Edition.
Introdunction
I have been using the Databricks platform for almost five years. I feel this is a great opportunity to share valuable information for anyone interested in understanding Databricks, its use cases, and why it is rapidly gaining popularity among data professionals.
Databricks is a data intelligence platform that provides enterprise-grade data solutions designed to address challenges associated with traditional data systems. Databricks uses a lakehouse architecture, overcoming limitations associated with traditional data warehouses and data lakes. I’ve described this architecture in detail in an earlier blog post.
The lakehouse architecture provided by Databricks offers the best of both worlds—data warehouses and data lakes. Organizations can efficiently store, manage, and leverage various types of data to generate insights and maximize the value of their data.
High Level Architecture
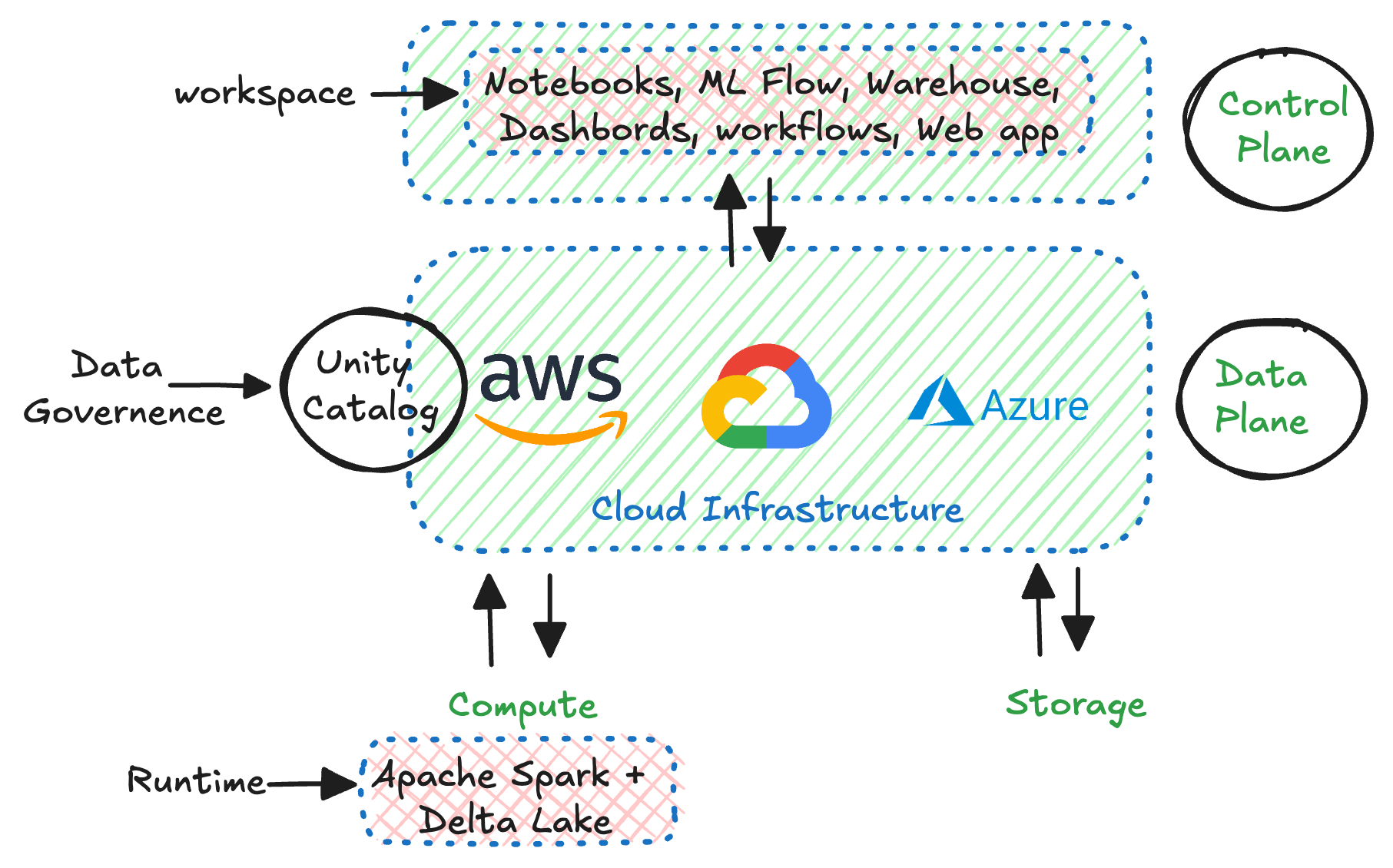
Databricks architecture has 4 primary components:
- Cloud Infrastructure - A multi-cloud platform enabling users to leverage their own cloud accounts for data storage and compute resources.
- Databricks Runtime - Includes essential libraries such as Apache Spark, Delta Lake, and DBFS for data processing.
- Data Goverenence - Managed by Unity Catalog, responsible for data governance. More information can be found in my blog here.
- Workspace - Provides comprehensive tools for data engineers, AI/ML engineers, and data scientists. This includes notebooks, workflows (job orchestration), serverless query engines, dashboards, and more.
These components can be categorized into two groups:
- Control Plane - Components managed by Databricks, such as the web application, cluster management, job orchestration, REST APIs, CLI, etc.
- Data Plane - Contains compute resources (clusters running Databricks Runtime) and primary storage. Since the data plane resides in the client’s cloud infrastructure, clients maintain and manage their data and associated policies effectively. DBFS and Unity Catalog reside within the data plane.
Apache Spark
pache Spark is a distributed computing engine developed at UC Berkeley, which processes data in-memory. Databricks was created by the original developers of Apache Spark, addressing infrastructure and maintenance challenges associated with Spark through a unified platform.
Apache Spark itself is an extensive topic. Databricks simplifies Spark usage by providing an easy-to-use ecosystem for processing data. I have a separate series about apache spark which you can find here.
Getting started with databricks
In my opinion, the easiest way to begin is by signing up for the Databricks Community Edition. Community edition does not have all the features available in the enterprise vesion but it is a good starting point. Here are my recommendations for getting started:
- Pick a dataset that you like from websites like kaggle or APIs.
- Upload the data in dbfs.
- Process the data using spark and create a bronze/raw delta table.
- Perform some transformation to create silver layer delta table.
- Prepare the analytics ready delta table.
Next steps
I will be covering various topics in greater detail in upcoming posts. These will provide further clarity on how to effectively use Databricks and integrate it into your architecture or data solutions.