
What is a data lake?
A data lake is an organization-wide repository of various forms of data, including structured, semi-structured, and unstructured data sources. Companies can perform various operations on top of this data lake, including driving dashboards/BI applications, running ML algorithms, or any LLM-related use cases like RAG. In contrast to a data warehouse, which can store structured data sources, a data lake can hold multiple types of data like photos, video feeds, IoT data, CSV files, etc. Typically these data lakes are built on cloud storage like AWS S3 or Azure Blob Storage.
Since data lakes hold raw forms of data, in order to make data more usable and easy to manage, we need to have a provision of a catalog that can help organize the data in a better and structured way. A catalog also allows better control over access and governance. Unity Catalog provided by Databricks is one such example.
A data lake allows a separation between storage and compute. This is very beneficial in terms of cost. Until the data is used for computation, only storage costs will be applied, which are becoming cheaper and cheaper over time. Data lakes are used as a staging area for the data warehouse (ELT approach), where data is first stored in the data lake and after that it is processed and pushed to a data warehouse. Due to the loosely structured nature of a data lake, the data can be malformed or corrupt, which is known as a “data swamp”. Another common issue with data lakes is that there is no isolation between reads and writes. There is no concept of transactions, which can lead to inconsistent results.
What is a data warehouse?
It is a central repository of structured data within an organization. This central repository helps drive various analytics and BI use cases within an organization. In the traditional approach, there was no isolation between compute and storage, so as the data grows, the cost associated with managing the warehouse infrastructure also increases significantly. A data warehouse is built for reliability and supports schema enforcement, type safety, and user- and group-level permissions. Due to the limitation of not being able to store unstructured data, ML/AI data sources like images, video feeds, etc. need to be pushed to a data lake.
Dual-Tier Architecture (Accommodating both the DWH and Data Lake)
Due to increasing use cases in ML and AI, organizations have to manage both data lakes and data warehouses simultaneously. It is a separate task/effort to make sure the data lake and the data warehouse remain in sync at all times. Consider the following diagram to understand the dual-tier architecture:
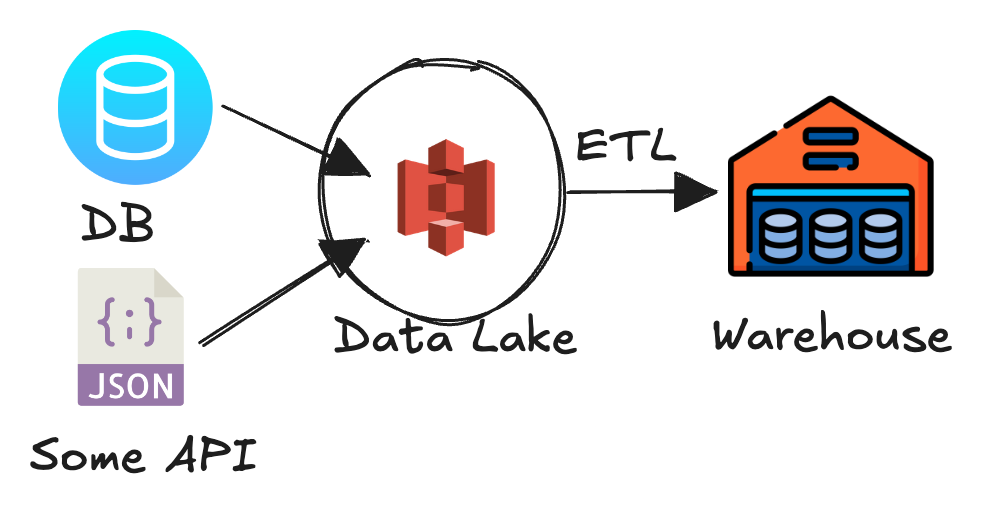
Here is how data flows through the architecture:
- From the source system, which can be another DB/File/REST API, data is pushed to the data lake (S3). This can be done using a tool like Airbyte or custom code scheduled using Mage or Airflow.
- Once data lands in the data lake, it can be transformed and stored in a staging location on the same data lake.
- Another job will pick up that staging data and push it to the data warehouse.
Here, the data lake can support ML use cases, while the DWH can support BI/Analytics use cases.
Lakehouse architecture
It combines the best of both worlds—data warehouse and data lake. This architecture allows one standard single system that can be utilized across the team based on the use case. Having a single system means there is just a single source of truth. The pain associated with syncing the data lake and data warehouse no longer exists, which is huge in terms of development and maintenance efforts.
Here are some high-level features of lakehouse, as specified in “Delta Lake: The Definitive Guide”:
- Transaction support
- Schema enforcement and governance
- BI support through SQL and JDBC support
- Separate storage and compute
- Open API and open data format
- Streaming support
- SQL to deep learning workloads supported
Delta Lake
Delta Lake is an open-source storage layer. It comes with Databricks Runtime and is the default format. Delta Lake makes it possible to build a single data platform that can perform high-performance queries for BI or streaming workloads.

Here are some high-level points that can help you understand Delta Lake in a better way:
- Brings consistency with ACID transactions and audit trail
- It is a part of the Databricks ecosystem
- Delta log keeps track of every transaction that happens on a Delta table
- Log is a JSON file with information on each and every operation that happens (all CRUD operations)
- Data is stored in Parquet format
Summary
In this article, I explained the concepts around data lakes, data warehouses, and data lakehouses. Delta Lake is a storage layer that is primarily used alongside Databricks. In the next blog, I am going to provide some hands-on code to showcase the features of Delta Lake, which will make things clearer.
Delta Lake and Unity Catalog used with the medallion architecture will make a very powerful, well-organized, and well-governed data system, which is very flexible and scalable.
Add a call-to-action encouraging readers to subscribe or comment with specific features they’d like covered in future posts.